Googleが新たに発表したAIアーキテクチャ「Titans」と理論フレームワーク「MIRAS」は、AIの「記憶」のあり方に大きな変化をもたらす技術だ。
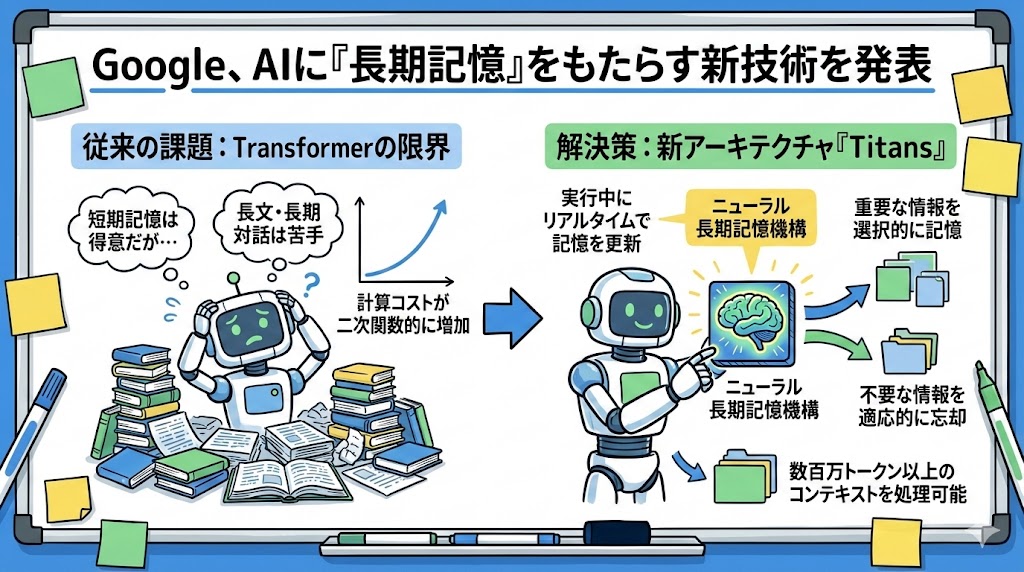
従来のAIモデル、特にTransformer型は短期的な文脈は非常に得意だが、過去の膨大な情報を一貫して保持・更新し続けるのには限界があった。
数百万トークンを超えるような超・長文脈処理や、長時間の履歴を取り扱う際には、大きな計算コストや性能低下などの問題がつきまとっていた。
Titansは、AIが実行中にコアな長期メモリをリアルタイムで更新できる設計が導入されている。
ここで使われる記憶モジュールは、単なる固定ベクトルや行列だけでなく、多層パーセプトロン(ニューラルネットワーク)を基盤に組み込まれていて、長期記憶の機構として機能する。
特徴的なのは「サプライズ」という、予想外の情報を計算し、記憶の優先順位や保持・忘却を柔軟に調整する仕掛けだ。
このため、重要と判断された情報は選択的に記憶され、不要な部分は適応的に忘却されるようになっている。
結果、従来は数十万トークンで頭打ちだった文脈処理が、数百万トークン規模でも効率よく扱えるようになった。
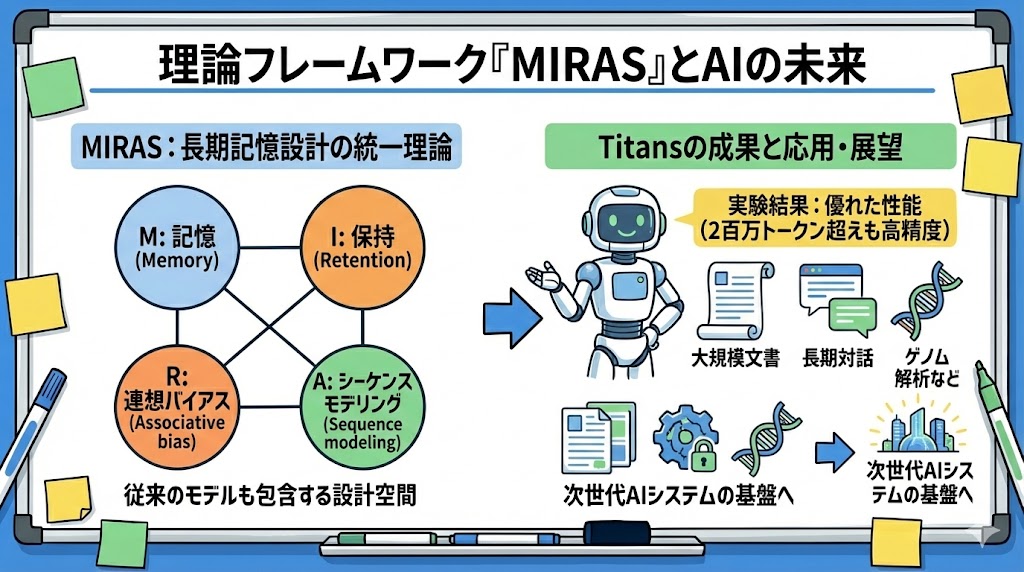
「MIRAS」は、Memory, Retention, Associative bias, Sequence modeling の頭文字を取ったもので、長期記憶の設計を統一的に解釈・構築できる理論的な枠組みとして機能している。
従来のTransformerやRNN系も、この枠組みでは“特殊ケース”として捉え直すことができるらしい。
記憶アーキテクチャや注意バイアス、記憶更新アルゴリズムの設計選択が理論的に整理されていて、新旧の情報を無駄なく統合しつつ、本質的な知識を効果的に失わないデザイン空間が提供されているのが面白いポイントだ。
実験では、このTitansアーキテクチャが近年提案されてきたリカレント系モデルや従来のTransformer系と比べて、言語モデルタスクや長文理解タスクで高い性能を発揮したことが示されていた。



特に200万トークンを超える極長コンテキストで、高精度な推論が維持できるのはとても興味深い。
この技術は単なるAIの処理速度や効率化に留まらず、大規模な文書解析、長期間に渡る対話履歴や会話記録の一貫処理、時系列データやバイオ系のゲノム解析まで幅広く応用できる基盤になりそうだと感じる。
今後AIモデルの知識保持や記憶能力をどこまで“人間らしく”拡張できるか、その土台となる設計思想・理論が提示されたと言える。
プログラマーとしては、新しいモデルのアーキテクチャがどのように既存フレームワークと統合されていくのか、実装上の柔軟性やハードウェアとの相性など、今後の展開に非常に期待している。

