近年、画像生成AIの進化によって、誰でも簡単にテキストから多様な画像を生み出せる時代が到来しました。
一見すると、その表現は無限に広がっているように見えます。
しかし最近、スウェーデンのダーラナ大学の研究者チームは非常に興味深い実験を行い、新たな事実を明らかにしました。
研究チームはまず、Stable Diffusion XLという画像生成AIに「自然の囲いの中、一人が座り、8ページの古本を手にしている」というようなシンプルなテキストプロンプトを入力して画像を生成しました。
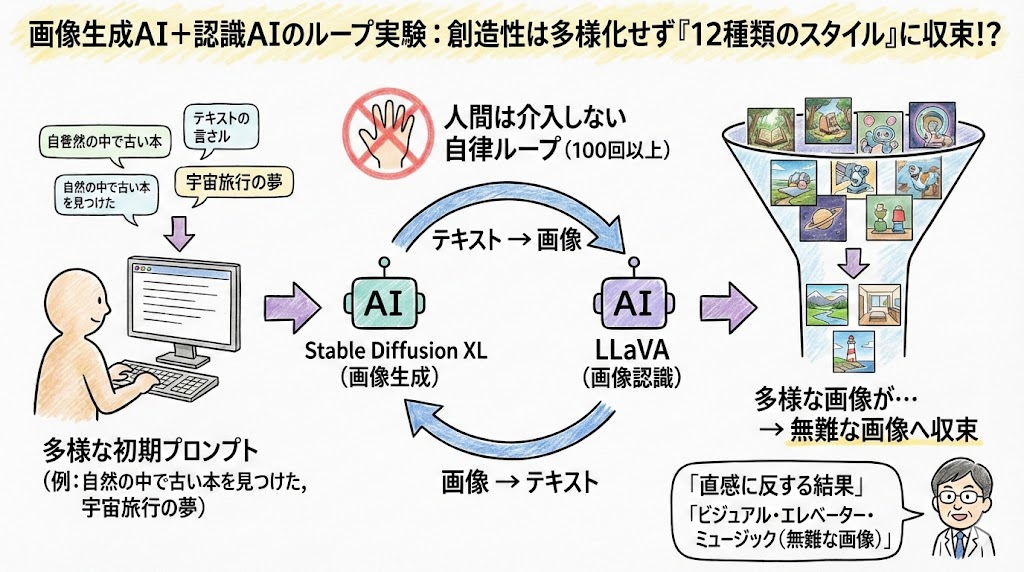
次にその画像を、LLaVAという画像認識AIに読み取らせ、その内容をテキストで説明させます。
得られた説明を再びStable Diffusion XLに入力して画像を生成し、この「画像→テキスト→画像→テキスト…」というサイクルを100回以上繰り返しました。
この伝言ゲームのようなループの中で、最初は多様だった画像が徐々に変化し、やがて不思議な収束を見せ始めます。
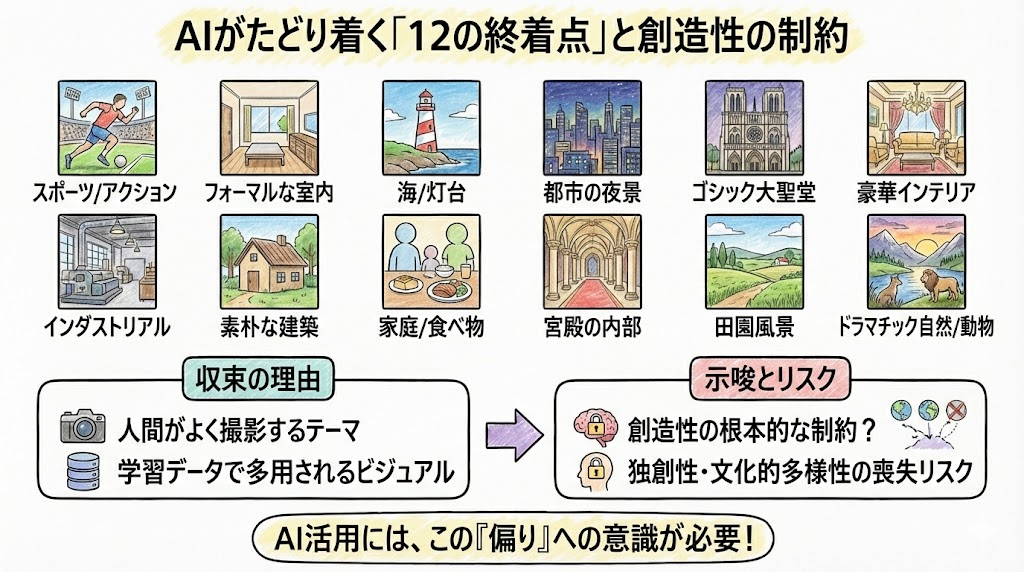
最終的には、テーマやプロンプトに関わらず、「スポーツアクション」「室内のフォーマル空間」「灯台のある海景」など、12種類のスタイルやモチーフのいずれかにほぼ必ず落ち着くことが判明しました。
人間同士の伝言ゲームでは、解釈に個性や偏見が反映されるため、元のメッセージが奇抜な内容に変化してしまうことも多いですよね。
しかしAI同士のループでは、多様な意味や創造性が拡がるどころか、すぐに同じような無難なイメージばかりが繰り返されるようになるのです。
これは「ビジュアル・エレベーター・ミュージック」、つまりエレベーターのBGMのような誰にも嫌われない平均的な画像に収束する現象だ、と研究者は表現しています。



この実験を聞いた時、「どうしてこんなことが起きるのか?」とすごく興味を持ちました。
画像生成AIも画像認識AIも、実際には莫大なデータセットから学習しています。
だからこそ、どんなに個性的なプロンプトを与えても、繰り返しの中で“良くあるパターン”“一般的な題材”に引っ張られていくのでしょう。
これはプログラムやデータセット設計の根本的な限界とも言えますし、美学的な多様性をもっと守るしくみを考える必要性も感じました。
この仕組みや限界を意識せず、生成AIを活用してしまうと、じつは多様性や独創性を失っていくリスクもありそうです。
一見自由な創造性に満ちたAIの世界も、アルゴリズムやデータの選び方でかなり制約されている。
こうした現象を知ったうえで、AIをどう活用していくか、プログラマーとしても考えさせられる研究でした。